Distributed Story Pipeline Data Model
The design and development of ChronoKeeper and ChronoGrapher components follow the distributed Story Pipeline Data Model.
Story is a time-series data set that is composed of individual log events that the client processes running on various HPC nodes generate over time and assign to the story of their choice. Every log event is identified by the StoryId of the story it belongs to, the ClientId of the application that generated it and the timestamp that ChronoLog Client library generates at the moment it takes ownership of the log event (we also augment the timestamp with the client specific index to handle the case of the same timestamp being generated on different threads of client application). As the time goes on the event travels through the different tiers of the ChronoLog data collection pipeline: ChronoKeeper processes running on the compute nodes being the first tier, ChronoGrapher processes running on the storage nodes - the second tier, and eventually makes it to the third tier represented by the permanent storage layer. Each process involved in collection of the events for the specific story assumes ownership of the events for some duration of time and while it has the ownership it does its best to group events by StoryId and timestamp into appropriate StoryChunks.
StoryChunk is a set of events for the same story that fall into the time range [start_time, end_time) including the start_time and excluding the end_time, events within the StoryChunk are ordered by the event_sequence=(timestamp + ClientId + index).
StoryPipeline is the set of StoryChunks ordered by their start_time values. For any Story with active contributors and/or consumers segments of the StoryPipeline can be distributed over several processes, nodes, and tiers at any moment in time (see the Story Pipeline Model illustration below).
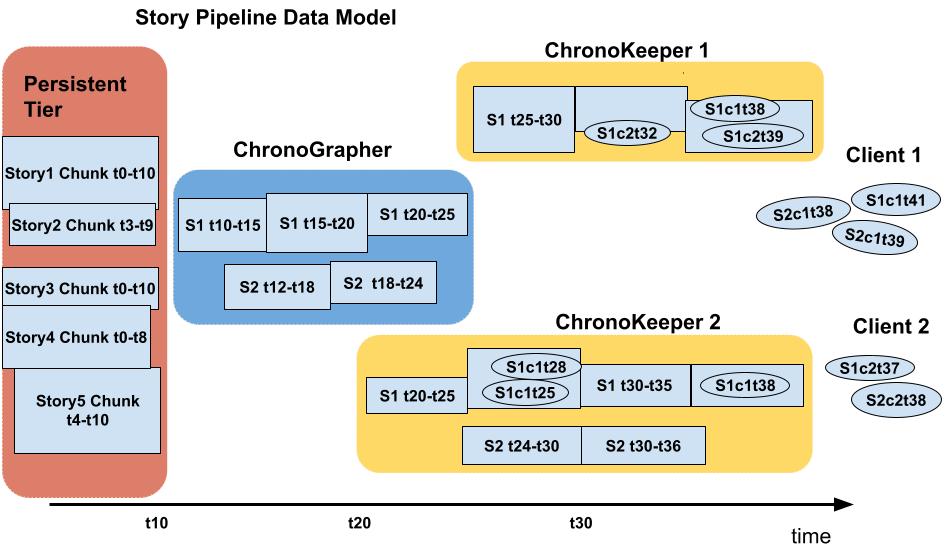
ChronoKeeper retains ownership of the specific StoryChunk for the duration of a configurable acceptance window to accommodate for the network delays in event arrival time, and when the window expires it sends the StoryChunk to the ChronoGrapher. Because each client application can send log events to multiple ChronoKeepers, each ChronoKeeper involved in the same story recording can only have the subset of the story events for the same time range. When the ChronoGrapher process receives these partial StoryChunks for the same Story it takes responsibility for merging the partial StoryChunks into its StoryPipeline. StoryChunks in the ChronoGrapher segment of the StoryPipeline are likely to have longer time ranges (granularity) and longer acceptance window as the ChronoGraphers. When the acceptance window period for the merged StoryChunk under ChronoGrapher responsibility expires the ChronoGrapher extracts it into a persistent storage format and records it into the persistent storage layer.
Using a group of ChronoKeepers running on different HPC nodes to record individual events from multiple clients for the same Story allows us to distribute the immediate ingestion of events and parallelize early sequencing of the events into partial StoryChunks over different HPC nodes. Moving of the events in presorted batches that the StoryChunks are instead of moving individual events between the compute and storage nodes provides for higher overall throughput of event data across the network.