Architecture
ChronoLog leverages physical time for total ordering and utilizes multiple storage tiers for 3D data distribution -- horizontal, vertical, and temporal.
The Shared Log: A Universal Primitive
A distributed shared log is one of the most powerful abstractions in systems design. It can serve as the foundation for a remarkably wide range of distributed data infrastructure.
ChronoLog's core challenge: how to balance log ordering, write-availability, capacity scaling, parallelism, entry discoverability, and performance -- all at once.

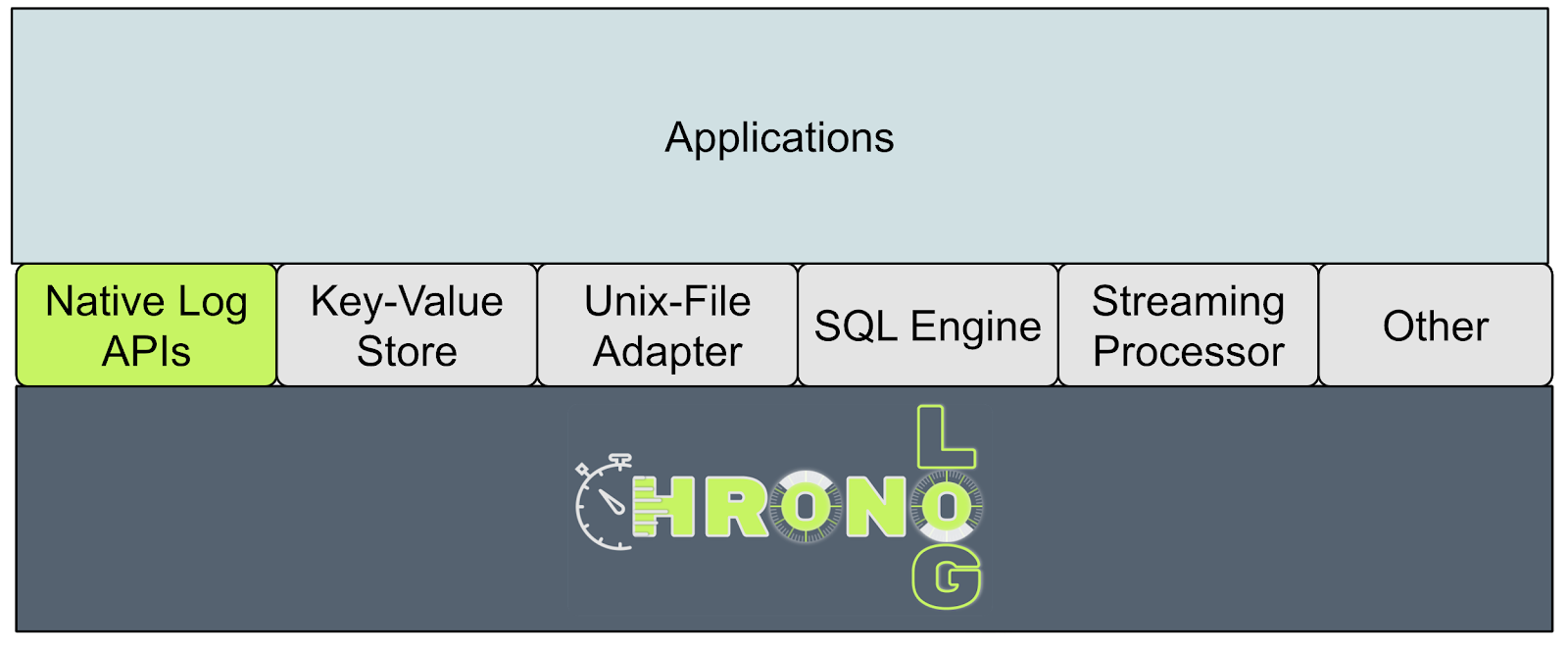
ChronoLog system design: clients, ChronoVisor, ChronoKeeper, ChronoGrapher, and storage tiers
Distributed Shared Log Paradigm
ChronoLog organizes data around the distributed shared log paradigm. Applications across Edge and HPC systems produce and process log data through a common storage model.
Data flows from ChronoKeeper (hot tier) through ChronoGrapher (warm tier) to ChronoStore (cold tier) automatically, matching I/O production rates with elastic resource provisioning.

The distributed shared log paradigm across Edge and HPC domains
Core Components
ChronoVisor
Central coordinationHandles client connections, holds chronicle metadata, acts as the global clock enforcing time synchronization. Deployed on a head node. ChronoVisor is the entry point for all client operations -- it resolves chronicle names to their physical locations and coordinates the distributed clock protocol that keeps all nodes synchronized within a bounded skew.
ChronoKeeper
Fast ingestion tierServes record() and playback() operations. Stores events in a distributed journal on compute nodes with fast flash storage. ChronoKeeper nodes are co-located with application processes, enabling zero-copy writes via RDMA and achieving microsecond-level ingestion latency.

ChronoKeeper features: record/playback operations, distributed journaling, RDMA transport
ChronoGrapher
Aggregation & flushingContinuously ingests events from ChronoKeeper using a DAG pipeline: event collection, story building, and story writing. Elastic and real-time. ChronoGrapher assembles individual log entries into time-ordered stories (StoryChunks), then flushes them to lower storage tiers while maintaining the global ordering invariant.

ChronoGrapher DAG pipeline: event collection, story building, story writing
ChronoPlayer
Historical readsExecutes replay() operations across all storage tiers. Implements real-time, decoupled, and elastic data retrieval. ChronoPlayer can serve replay requests from any tier -- hot data from ChronoKeeper, warm data from ChronoGrapher's intermediate storage, or cold data from ChronoStore's HDF5 backend -- transparently merging results into a single ordered stream.

ChronoPlayer: real-time, decoupled, and elastic data retrieval across tiers
ChronoStore
Persistent storageManages intermediate and backend storage (HDF5). Can grow or shrink resources dynamically for elastic capacity. ChronoStore provides the cold tier in the storage hierarchy, persisting StoryChunks in HDF5 containers optimized for sequential and range-based access patterns typical of log data.
Dealing with Physical Time
Using physical time to order events across distributed nodes introduces real challenges. ChronoLog provides solutions to each of them.
Clock Uncertainty
Different machines have different clock offsets and drift rates. ChronoLog tames this by having server nodes synchronize with ChronoVisor during initialization and periodically thereafter. Clients use ChronoTicks as relative time distances from a base clock, eliminating the need for globally synchronized wall clocks.
Backdated Events
Network non-determinism means events may arrive after later events, violating chronicle immutability. ChronoLog defines an Acceptance Time Window (ATW) -- a moving window equal to twice the measured network latency -- within which out-of-order events are gracefully absorbed and correctly ordered.
Event Collisions
At coarser time granularities, multiple events may map to the same ChronoTick. ChronoLog handles collisions with configurable semantics: Idempotent (last write wins), Redundancy (keep all), Ordering (preserve arrival order), and Sequentiality (maintain strict sequence). The right choice depends on workload requirements.
Software Contributions
Software contributions: core services, client library, and plugins
ChronoLog's software ecosystem spans three layers: the core distributed services (ChronoVisor, ChronoKeeper, ChronoGrapher, ChronoPlayer, ChronoStore), a client library (libchronolog) providing the chronicle API, and a plugin framework enabling SQL queries, streaming analytics, KV stores, and ML pipelines.
The system is implemented in C++17 with RDMA and TCP transport backends, HDF5 for persistent storage, and a modular architecture that allows new plugins to be developed independently.
Feature Comparison
| Feature | Bookkeeper / Kafka / DLog | Corfu / SloG / ZLog | ChronoLog |
|---|---|---|---|
| Locating the log-tail | Locking | Locking | Lock-free |
| I/O isolation | Yes | No | Yes |
| I/O parallelism (readers-to-servers) | 1-to-N | M-to-N | M-to-N |
| Storage elasticity | Manual | Manual | Automatic |
| Log hot zones | Yes | Yes | No |
| Log capacity | Limited | Limited | Infinite |
| Operation parallelism | Limited | Limited | Full |
| Granularity of data distribution | Coarse (stripe) | Fine (entry) | Fine (time-chunk) |
| Log total ordering | Eventual | Immediate | Total |
| Log entry visibility | End of epoch | After sequencing | Immediate |
| Storage overhead per entry | Moderate | High | None |
| Tiered storage | No | No | Yes |
Auto-Tiering
Real-time flushing
Data flows to lower tiers continuously as it arrives.
Tunable parallelism
Resource elasticity adjusts to incoming traffic patterns.
Device-aware access
Storage operations are optimized per device type.
Server-pull eviction
Decoupled from client operations for minimal impact.